데이터 처리 | Data Processing
KT 에이블스쿨 6기 데이터 처리에 진행한 강의 내용 정리한 글입니다.
데이터프레임 변경
- 열 이름 변경:
columns속성을 통해 모든 열 이름을 변경하거나rename()메소드를 통해 지정한 열 이름을 변경할 수 있습니다. - 열 추가:
insert()메소드를 사용하여 원하는 위치에 열을 추가할 수 있습니다. - 열 삭제:
drop()메소드를 사용하여 열으 삭제할 수 있습니다. (axis=0: 행 삭제, axis: 열 삭제) - 값 변경: 열 전체 값을 변경, 조건에 의한 값 변경,
map()메소드를 통한 기존 값으 다른 값으로 변경할 수도 있습니다.cut()메서드를 통해 숫자형을 범주형 변수로 변환도 가능합니다.
| 데이터프레임 변경 | 예시 |
|---|---|
| 열 이름 변경 | df.rename(columns={'old_name': 'new_name'}, inplace=True) |
| 열 추가 | df.insert(1, 'new_column', value) |
| 열 삭제 | df.drop('column_name', axis=1, inplace=True) |
| 값 변경 | df['column_name'] = new_value |
데이터프레임 결합
merge(join)
pd.concat: 인덱스, 열이름 기준으로 데이터프레임 구조에 맞게 합칩니다.pd.merge: 특정 열의 값 기준으로 데이터 값 기준으로 합칩니다.pivot():dataframe.pivot(index=, columns=, value=)의 형태를 띄며 groupby로 먼저 집계하고 집계된 데이터를 재구성합니다.
pd.concat | pd.merge | |
|---|---|---|
| 방향 | axis=0세로(행)로 합치기 칼럼 이름 기준 axis=1가로(열)로 합치기 행 인덱스 기준 | 옆으로만 병합 |
| 방법 | outer: 모든 행과 열 합치기(기본값)inner: 같은 행과 열만 합치기 | inner: 같은 값만, outer: 모두left: 왼쪽 df는 모두, 오른쪽 df는 같은 값만right: 오른쪽 df는 모두, 왼쪽 df는 같은 값만 |
| 예시 | pd.concat([df1, df2], axis=0) | pd.merge(df1, df2, how='inner') |
시계열 데이터 처리
시계열 데이터는 행과 행에 시간의 순서(흐름)가 있고 행과 행의 시간 간격이 동일한 데이터를 뜻합니다.
- 날짜 요소 뽑기: 날짜 타입의 변수로부터 날짜의 요소를 뽑아낼 수 있습니다.
- 이전 값 옆에 붙이기:
shift()메소드를 통해 시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 수 있습니다. - 이동 평균 구하기:
rolling().mean()메소드를 통해 시간의 흐름에 따라 일정 기간 동안 평균을 이동할 수 있습니다. - 이전 값과 차이 구하기:
diff()메소드를 통하여 특정 시점 데이터에서 이전시점 데이터와의 차이를 구할 수 있습니다.
| 날짜 요소 뽑기 | 이전 값 옆에 붙이기 | 이동 평균 구하기 | 이전 값과 차이 구하기 | |
|---|---|---|---|---|
| 예시 | df['columns_name'].dt.isocalendar() | df['columns_name'].shift() | df['columns_name'].rolling().mean() | df['columns_name'].diff() |
데이터분석 방법론
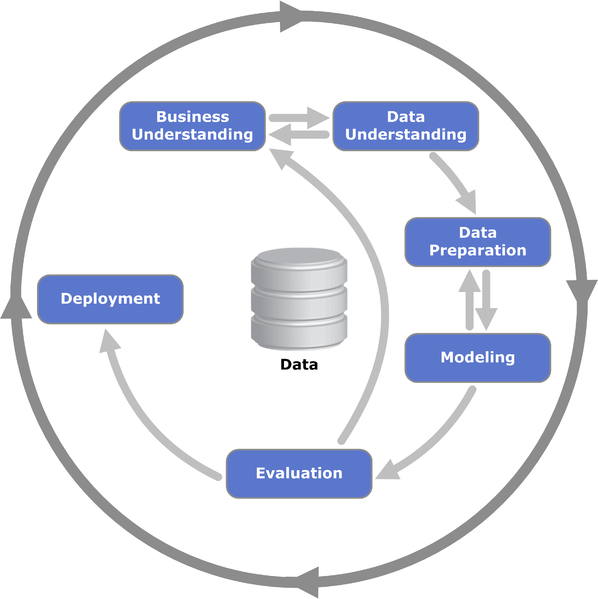
_CRISP-DM (Cross Industry Standard Process for Data Mining)_
- Business Understanding - 가설 수립
- 귀무가설: 기존 연구 결과로 이어져 내려오는 정설
- 대립가설: 기존의 입장을 넘어서기 위한 새로운 연구 가설
- 가설 수립 절차: 해결해야 할 문제(𝑦)를 정의하고, 이를 설명할 요인(𝑥)을 찾아 가설의 구조(𝑥 → 𝑦)를 설정하는 과정
- 데이터 분석 방향, 목표 결정
- Data Understanding - 데이터 탐색
- EDA(Exploratory Data Analysis): 개별 데이터의 분포, NA, 이상치, 가설이 맞는지 파악 → 탐색적 데이터 분석 (그래프, 통계량)
- CDA(Confirmatory Data Analysis): 탐색으로 파악하기 애매한 정보는 통계적 분석 도구(가설 검정) 사용 → 확증적 데이터 분석 (가설검정, 실험)
- EDA & CDA: 단변량 분석 → 이변량 분석
- Data Preparation
- 모든 셀에 값 존재
- 모든 값은 숫자
- 값의 범위 일치
- 수행 내용: 결측치 조치, 가변수화, 스케일링, 데이터 분할
- Modeling
- 데이터로부터 패턴을 찾는 과정
- 오차를 최소화하는 패턴
- 결과물: 모델(수학식으로 표현)
- Evaluation
- Deployment
시각화 라이브러리
수 많은 데이터를 한 눈에 파악하는 방법으로 그래프와 통계량 두 가지 방법이 있습니다.
- 목적: 비즈니스 인사이트를 파악하는 것입니다.
- 한계: 요약된 정보가 표현되므로 정보의 손실이 발생하고 요약하는 관점에 따라 해석의 결과가 달라질 수도 있습니다.
1
2
import matplotlib.pyplot as plt
import seaborn as sns
| 시각화 도구 | 선언 |
|---|---|
| 기본 라인차트 | plt.plot(x, y, data) |
| 그래프 출력 | plt.show() |
| 값 조정 | plt.xticks(rotation=각도)plt.yticks(rotation=각도) |
| 축 레이블 | plt.xlabel('x축 레이블')plt.ylabel('y축 레이블') |
| 그래프 타이틀 | plt.title('그래프 타이틀') |
| 범례 | plt.legend() |
| 그리드 | plt.grid() |
단변량 분석 - 숫자형
- 기초통계량:
df.describe()을 통해 정보의 대표값 확인 가능 (mean, median, mode, 사분위수) - 도수분포표: 구간을 나누고 빈도수 계산
| 시각화 | 설명 | 선언 |
|---|---|---|
| 히스토그램 | 구간의 개수에 따라서 파악할 수 있는 내용이 달라지므로 주의 | plt.hist(변수명, bins = 구간 수) |
| 밀도함수 그래프 (KDE plot) | 측정된(관측된) 데이터로부터 전체 데이터 분포의 특성을 추정 | sns.kdeplot(변수명) |
| Box Plot | 사전에 반드시 NaN 제외 | plt.boxplot() |
단변량 분석 - 범주형
- 범주별 빈도수:
df['column_name'].value_counts() - 범주별 비율:
df['column_name'].value_counts(normalize = True)
| 시각화 | 설명 | 예시 |
|---|---|---|
| sns.countplot | 범주별 빈도수가 자동으로 계산되고 bar plot으로 그려짐 | sns.countplot(x='column_name', data=df) |
| plt.bar | 범주별 빈도수를 직접 계산하여 결과를 입력해야 하며 bar plot으로 그려짐 | plt.bar(x, height, data) |
This post is licensed under CC BY 4.0 by the author.