딥러닝 | Deep Learning
KT 에이블스쿨 6기 딥러닝에 진행한 강의 내용 정리한 글입니다.
CRISP-DM
CRISP-DM: 비즈니스 이해 → 데이터 이해 → 데이터 준비 → 모델링 → 평가 → 배포
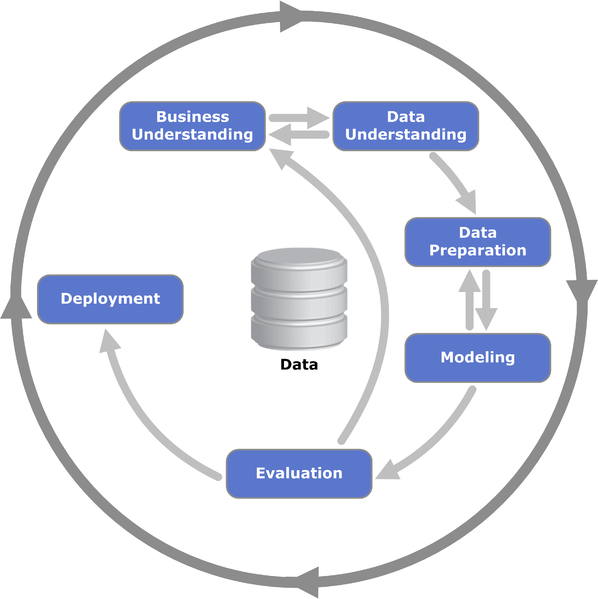
_CRISP-DM (Cross Industry Standard Process for Data Mining)_
딥러닝 개념 이해
가중치
- 파라미터(parameter)라고도 불립니다.
- 인공신경망에서 입력 신호의 중요도를 조절하여 학습과 예측에 영향을 미치는 값
- 이때 최적의 가중치를 가지면 최적의 모델인 오차가 가장 작은 모델이 됩니다.
- 가중치 조정
- 조금씩 weight를 조정
- 오차가 줄어드는지 확인
- 지정한 횟수만큼 혹은 오차가 줄어들지 않을 때까지
- 가중치 조정
학습절차
- 가중치에 (초기)값을 할당합니다.
- 초기값은 랜덤으로 지정
- (예측) 결과를 뽑습니다.
- 오차를 계산합니다.
- loss function
- 오차를 줄이는 방향으로 가중치를 조정
- Optimizer: Adam, GD 등
- 얼마만큼 조절할 지 결정하는 하이퍼파라미터: learning rate(lr)
- 다시 1번 단계로 올라가 반복합니다.
- 전체 데이터를 적절히 나눠서(mini batch) 반복: batch_size
- 전체 데이터를 몇 번 반복 학습할지 결정: epoch
- max iteration에 도달
- 오차 변동이 거의 없으면 끝
Regression
전처리
- Normalization(정규화)
- 모든 값의 범위를 0 ~ 1로 변환
- $X_{norm} = \frac{x - min}{max - min}$
- Standardization(표준화)
- 모든 값을 평균 = 0, 표준편차 = 1로 변환
- $X_{z} = \frac{x - mean}{std}$
딥러닝 구조
Input → Task1 → Task2 → Task3 → Output
- Input
- Input: Input(shape = ( , ))
- 분석단위에 대한 shape
- 1차원: (feature수, )
- 2차원: (rows, columns)
- Task
- 이전 단계의 Output을 Input으로 받아 처리한 후 다음 단계로 전달
- Hidden Layer
- layer 여러 개: 리스트[ ]로 입력
- Activation: 활성함수는 보통 ‘relu’를 사용
- output layer: 예측 결과가 1개
- Compile: 선언된 모델에 대해 몇 가지 설정한 후 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
- loss function(오차함수): 오차 계산을 무엇으로 할지 결정
- 회귀모델: mse
- 분류모델: cross entropy
- optimizer: 오차를 최소화하도록 가중치를 업데이트하는 역할
- Adam: 최근 딥러닝에서 가장 성능이 좋은 Optimizer로 평가
- learning_rate: 업데이트할 비율로 기울기에 곱해지는 조정 비율
- loss function(오차함수): 오차 계산을 무엇으로 할지 결정
- Epoch 반복횟수: 주어진 train set을 몇 번 반복 학습할 지 결정
- 최적의 값은 케이스마다 다름
- history: 학습을 수행하는 과정 중에 가중치가 업데이트되면서 학습 시 계산된 오차 기록
- Output
- Output: Dense( )
- 예측 결과가 1개 변수 (y가 1개 변수)
_딥러닝 구조_
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 분석단위의 shape
nfeatures = x_train.shape[1]
# 메모리 정리
clear_session()
# Sequential 타입
model = Sequential([ Input(shape = (nfeatures,)),
Dense(1) ])
# 모델 요약
model.summary()
# 모델 컴파일
model.compile(optimizer = Adam(learning_rate = 0.1), loss='mse')
# 모델 학습하기
history = model.fit(x_train, y_train, epochs = 20, validation_split=0.2).history
학습 곡선
- 모델 학습이 잘 되었는지 파악하기 위한 그래프
- 정답은 아니지만 학습 경향을 파악하는데 유용
- 각 Epoch마다 train error와 val error가 어떻게 줄어들고 있는지 확인
- 바람직한 학습 곡선
- 초기 epoch에서는 오차가 크게 줄고 오차 하락이 꺾이면서 점차 완만해짐
- 바람직하지 않은 학습 곡선
- 학습이 덜 된 경우
- 오차가 줄어들다가 학습이 끝남
- epoch 수 늘리거나 learning rate 크게 하기
- 오차가 줄어들다가 학습이 끝남
- train error가 들쑥날쑥인 경우
- 가중치 조정이 세밀하지 않음
- 조금씩 업데이트하여 learning rate을 작게 하기
- 가중치 조정이 세밀하지 않음
- 과적합이 일어난 경우
- train error는 계속 줄어드는데 val error는 어느순간부터 커지기 시작
- 너무 과도하게 학습이 된 경우
- Epoch 수 줄이기
- 학습이 덜 된 경우

_바람직하지 않은 학습곡선_
회귀 모델 평가
- R-squared($R^2$)
- 평균 모델의 오차 대비 회귀모델이 해결한 오차의 비율
- 회귀모데링 얼마나 오차를 해결(설명)했는지를 나타냅니다.
- 결정계수, 설명력이라고 부르기도 합니다.
- $R^2 = \frac{SSR}{SST} = 1 - \frac{SSE}{SST}$
이진분류
- Node의 결과를 변환해주는 활성화 함수(sigmoid)가 필요
- 예측 결과: 0 ~ 1 사이 확률 값
- 예측 결과에 대한 후속 처리: 결과를 .5 기준으로 잘라서 1, 0으로 변환
- 이진 분류 모델에서 사용되는 loss function: binary_crossentropy
- $ -\frac{1}{n} \sum_{}^{} \left( y \cdot \log\hat{y} + (1 - y) \cdot \log(1 - \hat{y}) \right) $
딥러닝 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 분석단위의 shape
nfeatures = x_train.shape[1]
# 메모리 정리
clear_session()
# Sequential 타입
model = Sequential([ Input(shape = (nfeatures,)),
Dense( 1, activation='sigmoid')])
# 모델 요약
model.summary()
# 모델 컴파일
model.compile(optimizer = Adam(learning_rate = 0.1), loss='binary_crossentropy')
# 모델 학습하기
history = model.fit(x_train, y_train, epochs = 20, validation_split=0.2).history
분류 모델 평가
오분류표
\[\text{정분류율, 정확도(Accuracy)} = \frac{TP + TN}{TP + TN + FP + FN} \quad \quad \quad \text{민감도, 재현율 (Recall)} = \frac{TP}{TP + FN}\] \[\text{정밀도 (Precision)} = \frac{TP}{TP + FP}\quad \quad \quad F1 \text{ Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\]다중분류
- 다중분류 모델에서 Output Layer의 node 수는 y의 범주 수와 같습니다.
- 다중분류 모델의 출력층
- 노트수: 다중 분류 클래스의 수와 동일
- Softmax: 각 Class별(Output Node)로 예측한 값을, 하나의 확률값으로 변환
- $\text{softmax}(x_i) = \frac{e^{x_i}}{\sum e^{x_i}}, \quad e \approx 2.718 \ldots$
- 다중분류오차계산: Cross Entropy
- 실제 값 1인 Class와 예측 확률 비교
전처리
- 정수 인코딩
- Target의 class들을 0부터 시작하여 순차 증가하는 정수로 인코딩
- One-hot 인코딩
- 2차원 구조로 입력해야 함
- 정수 인코딩이 선행되어야 함
딥러닝 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 분석단위의 shape
nfeatures = x_train.shape[1]
# 메모리 정리
clear_session()
# Sequential 타입
model = Sequential([ Input(shape = (nfeatures,)),
Dense( 3, activation='softmax')])
# 모델 요약
model.summary()
# 모델 컴파일
model.compile(optimizer = Adam(learning_rate = 0.1), loss='sparse_categorical_crossentropy')
# 모델 학습하기
history = model.fit(x_train, y_train, epochs = 20, validation_split=0.2).history
활성화 함수
| Layer | Activation Function | loss | 기능 |
|---|---|---|---|
| Hidden Layer | ReLU | 좀 더 깊이 있는 학습 가능 Hidden Layer를 여러 층 쌓기 선형 모델을 비선형 모델로 변환 | |
| Output Layer | 회귀(X) | mse | X |
| 이진분류(sigmoid) | binary_crossentropy | 결과를 0,1로 변환 | |
| 다중분류(softmax) | sparse_categorical_crossentropy | 각 범주에 대한 결과를 범주별 확률 값으로 |
- 현재 레이어(각 노드)의 결과값을 다음 레이어(연결된 각 노드)로 어떻게 전달할지 결정/변환해주는 함수
- Hidden Layer: 선형함수를 비선형 함수로 변환
- Output Layer: 결과값을 다른 값으로 변환
- 주로 분류(Classification) 모델에서 필요
성능관리
모델링의 목적 & 복잡도
- 모델링의 목적
- 학습용 데이터에 있는 패턴으로 그 외 데이터(모집단 전체)를 적절히 예측
- 학습한 패턴(모델)은 학습용 데이터를 잘 설명할 뿐만 아니라 모집단의 다른 데이터(val, test)도 잘 예측해야 함
- 모델의 복잡도
- 학습용 데이터의 패턴을 반영하는 정도
- 단순한 모델: train, val 성능이 떨어짐
- 적절한 모델: 적절한 예측력
- 복잡한 모델: train 성능 높고, val 성능이 떨어짐
Underfitting & Overfitting
- Underfitting
- 너무 단순한 모델
- 학습 데이터의 패턴을 제대로 학습하지 못하는 경우
- Overfitting
- 너무 복잡한 모델
- 모델이 복잡해지면 가짜 패턴(혹은 연관성)까지 학습하는 경우
- 가짜 패턴
- 학습 데이터에만 존재하는 패턴
- 모집단 전체의 특성이 아님
- 학습 데이터 이외의 데이터셋에서는 성능 저하
적절한 모델
- 적절한 복잡도 지점 찾기
- 알고리즘(모델)마다 각각 복잡도 조절 방법이 있습니다.
- 복잡도(하이퍼파라미터)를 조절해가면서 train error와 validation error를 측정하고 비교
- 복잡도 조절 대상
- epoch와 learning_rate
- 모델 구조: hidden layer수, node수
- 미리 멈춤: Early Stopping
- 임의 연결 끊기: Dropout
- 가중치 규제하기: Regularization(L1, L2)
딥러닝 복잡도
- 딥러닝 모델의 복잡도 혹은 규모와 관련된 수: 파라미터(가중치) 수
- Input feature수, hidden layer수, node수와 관련
- Conv Layer인 경우 MaxPooling Layer를 거치면서 데이터가 줄어들어 파라미터 수 감소
- 파라미터 수가 큰 경우
- 복잡한 모델
- 연결이 많은 모델
- 파라미터가 아주 많은 언어 모델(LLM: Large Language Model)
미리 멈춤(Early Stopping)
- Early Stopping
- 반복 횟수(epoch)가 많으면 과적합될 수 있습니다.
- 항상 과적합이 발생하는 것은 아닙니다.
- 반복횟수가 증가할수록 val error가 줄어들다가 어느 순간부터 다시 증가할 수 있습니다.
- val error가 더 이상 줄지 않으면 멈춤 → Early Stopping
- 일반적으로 train error는 계속 줄어듭니다.
- Early Stopping 옵션
- monitor: 기본값 val_loss
- min_delta: 오차(loss)의 최소값에서 변화량(줄어드는 량)이 몇 이상 되어야 하는지 지정
- patience: 오차가 줄어들지 않는 상황을 몇 번(epoch) 기다려줄 건지 지정
- callbacks: epoch 단위로 학습이 진행되는 동안 중간에 개입할 task 지정
1
2
3
4
5
6
from keras.callbacks import EarlyStopping
# EarlyStopping 설정
es = EarlyStopping(monitor = 'val_loss', min_delta = 0, patience = 0)
model.fit(x_train, y_train, epochs = 100, validation_split = .2, callbacks = [es])
연결 임의로 끊기(Dropout)
- Dropout
- 과적합을 줄이기 위해 사용되는 규제(regularization) 기법 중 하나
- 학습시 신경망의 일부 뉴런을 임의로 비활성화 → 모델 강제로 일반화
- 학습 시 적용 절차
- 훈련 배치에서 랜덤하게 선택된 일부 뉴런을 제거
- 제거된 뉴런은 해당 배치에 대한 순전파 및 역전파 과정에서 비활성화
- 이를 통해 뉴런들 간의 복잡한 의존성을 줄여줌
- 매 epochs마다 다른 부분 집합의 뉴런을 비활성화 → 앙상블 효과
- Dropout 옵션
- hidden layer의 노드 중 지정한 비율만큼 임의로 비활성화
- 보통 0.2 ~ 0.5 사이의 범위 지정
- 조절하면서 찾아야하는 하이퍼파라미터
- Feature가 적을 경우 rate를 낮추고 많은 경우 rate를 높이는 시도
- hidden layer의 노드 중 지정한 비율만큼 임의로 비활성화
1
2
3
4
5
6
7
8
9
# Dropout 사용
model = Sequential( [Input(shape = (nfeatures,)),
Dense(128, activation= 'relu'),
Dropout(0.4),
Dense(64, activation= 'relu'),
Dropout(0.4),
Dense(32, activation= 'relu'),
Dropout(0.4),
Dense(1, activation= 'sigmoid')] )
중간 체크포인트 저장하기
- 각 epoch마다 모델 저장
- 이전 체크포인트의 모델들보다 성능이 개선된 경우에만 저장
1
2
3
4
5
6
# Keras 2.11 이상 버전에서 모델 확장자 .keras
cp_path = '/content/{epoch:03d}.keras'
mcp = ModelCheckpoint(cp_path, monitor='val_loss', verbose = 1, save_best_only=True)
# 학습
hist = model1.fit(x_train, y_train, epochs=50, validation_split=.2, callbacks=[mcp]).history
Functional API
- Functional
- 모델을 좀 더 복잡하게 구성
- 모델을 분리해서 사용 가능
- 다중 입력, 다중 출력 가능
- 레이어: 앞 레이어 연결 지정
- Model 함수로 시작과 끝 연결해서 선언
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 모델 구성
input_1 = Input(shape=(nfeatures1,), name='input_1')
input_2 = Input(shape=(nfeatures2,), name='input_2')
# 입력을 위한 레이어
hl1_1 = Dense(10, activation='relu')(input_1)
hl1_2 = Dense(20, activation='relu')(input_2)
# 두 히든레이어 옆으로 합치기(= pd.concat)
cbl = concatenate([hl1_1, hl1_2])
# 추가레이어
hl2 = Dense(8, activation='relu')(cbl)
output = Dense(1)(hl2)
# 모델 선언
model = Model(inputs = [input_1, input_2], outputs = output)
시계열 모델링 기초
- 시간의 흐름에 따른 패턴을 분석
- 흐름을 어떻게 정리할 것인지에 따라 모델링 방식이 달라집니다.
- y의 이전 시점 데이터들로부터 흐름의 패턴을 추출하여 예측
- ML 기반
- 특정 시점 데이터들(1차원)과 예측 대상 시점($y_{t+1}$)과의 관계로부터 패턴을 추출하여 예측
- 모델 구조: $y_{t+1} = w_0 + w_1 x_{1t} + w_2 x_{2t} + w_3 x_{3t} + w_4 y_t$
- 시간의 흐름을 x변수로 도출하는 것이 중요
- DL 기반
- 시간흐름 구간(timesteps) 데이터들(2차원)과 예측대상시점($y_{t+1}$)과의 관계로부터 패턴 추출
- 분석 단위를 2차원으로 만드는 전처리 필요 → 데이터셋은 3차원
- ML 기반
- 절차
- y 시각화, 정상성 검토
- 모델 생성
- train_err(잔차) 분석
- 검증(예측)
- 검증(평가)
RNN
- SimpleRNN
- 노드 수 1개 → 레이어의 출력 형태: timesteps * 노드수
- return_sequences: 출력 데이터를 다음 레이어에 전달할 크기 결정
- True: 출력 크기 그대로 전달 → timesteps * 노드수
- False: 가장 마지막(최근) hidden state 값만 전달 → 1 * 노드수
- return_sequences: 출력 데이터를 다음 레이어에 전달할 크기 결정
- 노드 수가 여러 개일 경우
- return_sequences
- 마지막 RNN Layer를 제외한 모든 RNN Layer: True
- 마지막 RNN Layer: False와 True 모두 사용 가능
- return_sequences
- 노드 수 1개 → 레이어의 출력 형태: timesteps * 노드수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 데이터 x, y로 분리하기
x = data.loc[:, ['AvgTemp']]
y = data.loc[:,'y']
# 스케일링
scaler = MinMaxScaler()
x = scaler.fit_transform(x)
# 3차원 데이터셋 만들기
x2, y2 = temporalize(x, y, 4)
# 데이터 trian, val로 분리하기
x_train, x_val, y_train, y_val = train_test_split(x2, y2, test_size= 53, shuffle = False)
# 분석단위의 shape
timesteps = x_train.shape[1]
nfeatures = x_train.shape[2]
# 모델 구조 설계
model = Sequential([Input(shape = (timesteps, nfeatures)),
SimpleRNN(8),
Dense(1)])
# 모델 컴파일 및 학습
model.compile(optimizer = Adam(0.01), loss = 'mse')
hist = model.fit(x_train, y_train, epochs = 100, verbose = 0, validation_split = .2).history
LSTM
- RNN의 장기 의존성(long term dependencies) 문제 해결
- 구조
- time step 간에 두 종류의 상태 값 업데이트 관리
- Hidden State 업데이트
- 업데이트된 Cell State와 Input, 이전 셀의 hidden state으로 새 hidden state 값 생성해서 넘기기
- Cell State 업데이트: 긴 시퀀스 동안 정보를 보존하기 위한 상태값이 추가
- Forget Gate
- Input Gate
- 구조

This post is licensed under CC BY 4.0 by the author.