파이썬 프로그래밍 | Python Programming
KT 에이블스쿨 6기 파이썬 라이브러리 & 프로그래밍에 진행한 강의 내용 정리한 글입니다.
자료형(list, dictionary, tuple)
여러 값을 한꺼번에 저장하고 관리하기 위한 자료형입니다.
| 리스트 (List) | 딕셔너리 (Dictionary) | 튜플 (Tuple) | |
|---|---|---|---|
| 정의 | 순서가 있는 변경 가능한 구조 | 키와 값 쌍으로 이루어진 변경 가능한 구조 | 변경 불가능한 구조 |
| 선언 | 대괄호([])로 선언 list() 함수를 통해 선언 | 중괄호({})로 선언, dict() 함수를 통해 선언 (중괄호만 사용할 경우 집합(set) 자료형으로 인식되므로 주의) | 소괄호(())로 선언 tuple() 함수를 통해 선언 |
| 예시 | list_a = [1, ‘5’, 7, 9.3] | dic_a = {‘name’: ‘mark’, ‘age’: 23} | tup_a = (2, 3, ‘7’) |
흐름 제어(조건문과 반복문)
연산자
조건에 따라 실행 흐름을 제어하거나 반복하는 구문에서 사용하는 연산자입니다.
| bool 연산자 | 비교 연산자 | 논리 연산자 | |
|---|---|---|---|
| 정의 | 참(True) 또는 거짓(False) 값을 반환하는 연산자 | 두 값을 비교하여 그 결과를 참 또는 거짓으로 나타내는 연산자 | 하나 이상의 조건을 결합하여 참 또는 거짓을 반환하는 연산자 |
| 종류 | True, False | ==, !=, <, >, <=, >= | and, or, not |
조건문
if~ elif~ else: 위에서 아래로 조건을 확인합니다.
1
2
3
4
5
6
if (조건문1):
코드1
elif (조건문2):
코드2
else:
코드3
while loop: 주어진 조건이 참인 동안 계속해서 코드를 반복 실행하므로 조건이 변경되지 않으면 무한 루프가 발생할 수도 있습니다.
1
2
3
while 조건문:
코드
조건 변경문
반복문
range(a, b, c): a부터 b전까지 c씩 증가시킨 값입니다.
for loop: 주어진 시퀀스(리스트, 문자열, 튜플 등)나 범위에서 각 요소를 순차적으로 처리합니다.
1
2
for i in range(5):
print(i)
함수 생성 및 활용
def 키워드를 사용하여 정의하며 필요에 따라 매개변수를 전달하고 값을 반환합니다.
코드의 재사용성, 구조화, 가독성을 높이기 위해 사용합니다.
1
2
3
def 함수이름(매개변수1, 매개변수2):
실행할 코드
return 반환값
데이터 분석/모델링을 위한 데이터 구조
CRISP-DM: 비즈니스 이해 → 데이터 이해 → 데이터 준비 → 모델링 → 평가 → 배포
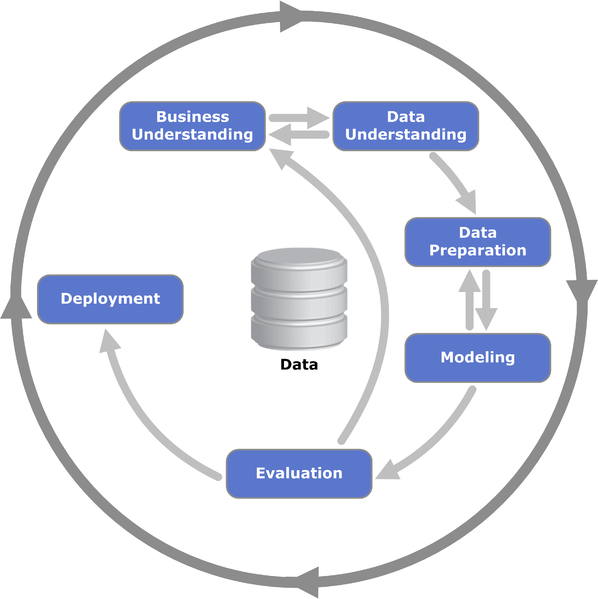
_CRISP-DM (Cross Industry Standard Process for Data Mining)_
- 분석할 수 있는 데이터: 범주형(명목형, 순서형), 수치형(이산형, 연속형)
- 데이터 행: 분석단위, 데이터 건수, 결과(y, target, label)
- 데이터 열: 정보, 변수, 요인(x, feature)
- 데이터 구조를 다루는 패키지: numpy(수치 연산), pandas(데이터 표현)
numpy 기초
수치 연산을 위해 배열(array)를 생성하고 다루는 패키지
1
import numpy as np
- Array 구조: Axis(배열의 각 축), Rank(축의 개수(차원)), Shape(축의 길이)
- Array 조회: arr1[행 인덱스, 열 인덱스], arr1[행 인덱스][열 인덱스], arr1[시작: 끝]
- Array 재구성: arr1.reshape(행, 열)
- Array 집계: np.sum(), np.mean(), np.std()
- 조건에 따라 다른 값 지정: np.where(조건문, 참일 때 값, 거짓일 때 값)
pandas 기초
데이터프레임을 통하여 데이터를 쉽게 처리하고 분석해주는 패키지
1
import pandas as pd
- 데이터프레임(Dataframe): 관계형 데이터베이스의 테이블 또는 엑셀 시트와 같은 형태 (2차원 구조)
- 시리즈(Series): 하나의 정보에 대한 데이터들의 집합으로 데이터에서 하나의 열을 떼어낸 것
- 데이터 프레임 정보 확인: df.info(), df.describe()
- 데이터 정렬: df.sort_index(ascending=False), df.sort_values(by=’’, ascending=False)
- 고유값 확인: df[’’].unique(), df[’’].value_counts()
- 데이터프레임 조회: df.loc[행 조건, 열 이름]
- 데이터프레임 집계: sum(), mean(), max(), min(), count()
- groupby(): df.groupby( ‘집계기준변수’, as_index = )[‘집계대상변수’].집계함수
This post is licensed under CC BY 4.0 by the author.